
Artificial Intelligence – Its Use in Exploration and Production – Part 3
Are we finally seeing AI fulfil its potential in oil and gas exploration?
In this series of articles, we are attempting to establish the background to the current resurgence in interest in Artificial Intelligence (AI), enabling us to have the best opportunity to use the technology to advantage. We have looked at how AI has evolved and at how Neural Networks (NN) work. Crucial to understanding the current resurgence of interest, this latest ‘Spring’ in the seasonal cycle of AI development, is what distinguishes Deep Learning from earlier implementations of NN.
In the mid-1990s Bertrand Braunschweig co-edited reviews of AI in oil exploration and production (E&P), consisting of papers presented at the CAIPEP, Euro-CAIPEP and AI Petro conferences. This may be taken as the state of the art at that time. Fuzzy logic and Expert Systems were still being discussed, but by consensus the tool of choice was NN and the papers primarily described applications of NN to problems in petrophysics, geochemistry, seismic geophysics, stratigraphy and others. Given that the Massachusetts Institute of Technology (MIT) describes Machine Learning (ML) and Deep Learning as developments of NN, we might usefully look at those reviews and ask what is different nearly 30 years later.

Electrical and instrument site service temperature transmitter on offshore oil and gas wellhead platform to monitor and record gas and oil temperature inside flowline pipe. Source: Shutterstock.
One obvious difference is a change of emphasis, from describing the technology to describing the results. The 1990s papers would start by both describing and justifying the choice of NN method (Multi-Layer Perceptrons, Radial Basis Function, Self-Organising Feature Map, Adaptive Resonance Theory, etc.) and the activation functions applied in the example of how technologies advance nodes (e.g., tangent hyperbolic, IMQE, Gaussian, Sigmoidal). Whilst the availability of methods has increased, the perceived need to explain has diminished. Nowadays, authors treat the underlying technology as just that, a technology on a par perhaps with choice of programming language or operating system.
Oily Fingerprints
A more useful comparison is with the applications. One from 1995 with which I am more familiar than most was a NN application for identifying oils from fluorescence spectra. It could learn to recognise ‘oily fingerprints’ by being taught on a training set. It is AI, it is a NN, and it learns, so how does this differ from what we now refer to as Machine Learning or Deep Learning (DL)?
The principal differences are in the size of the dataset and the number of parameters that characterise the data. The four factors listed earlier as driving the current interest in AI are access to data, computing power, development of the mathematical basis and commercial drive. Access to data is most commonly thought of as the internet but can also mean data accumulated by monitoring devices, such as those on production platforms. Increased computing power allows the processing of larger datasets and analysis of more characterising parameters.
Image Analysis Applications Dominate
If Braunschweig were to undertake his survey today, it would be dominated by image analysis applications, which were absent 30 years ago. One reason for this is that creating large datasets of images is now an integral part of many of the applications in routine use in E&P companies. For example, a petrographic data analysis application will collect up to 1,000 images each day of use, with detailed data and metadata going far beyond the simple classifications in facial recognition systems. The ML and DL frameworks provided by, for example, TensorFlow, MLFlow or PyTorch, then allow petrographers to perform their own AI investigations without needing a collaborating university research group.
However, more instructive in understanding how AI has progressed would be the applications that are not based on image analysis. Previous articles in GEO ExPro have discussed ML by analogy with cat/dog classification and facial recognition but we can gain a better understanding of how ML works if we look at an application that is more nearly a next generation (or even the one after next) from those showcased by Braunschweig. For this we can seek help from Solution Seeker, showcased in GEO ExPro Vol. 15, No. 3, 2018. With excellent academic credentials, a spin-off from the University of Science and Technology (NTNU), Norway, and a track record going back almost into pre-history in Deep Learning terms (founded in 2013) they have applied Deep Learning to production data: actual data from databases, rather than abstract information extracted from images.

The huge quantities of raw data generated during production can be used to optimise the process. © Solution Seeker.
Considering Solution Seeker’s products lets us see how the Deep Learning paradigm is both a natural progression from the earlier NN applications and a step-change in the application of AI to E&P workflows.
Deep Learning is based on access to large datasets, fast computing, and multi-level neural networks. Some popular examples of Deep Learning substitute a rule, a way to specify an objective function, for the large database of training examples. In this category are game-playing AIs that train themselves by playing games and revising strategies based on outcome, still with fast computing and sophisticated software. It is difficult to think of applications for this approach within E&P, as geology does not follow an arbitrary set of printed rules. We therefore need to identify large datasets on which our DL will operate. The most obvious sources are the large sets of tagged images, such as in the PETROG automated petrophysical solution. Additional software may be needed to turn these datasets into reliable exemplars, for example compensating for lighting, angle, scale, etc.
Solution Seeker’s approach is to turn commonly available datasets, such as historic monitoring data, into reliable exemplars and thus provide the first pillar of the DL paradigm. Indeed, as an example of how technologies advance at increasing speed due to their ability to feed on themselves, the Solution Seeker algorithms for preparing the data, and hence providing this first pillar, are themselves AI applications.
The Image Conundrum
The availability of large datasets may be questionable in many practical examples. A dataset consisting of a large number of images, for example, may require extensive preparation and cleaning in order to make it suitable for use by an image recognition application: an archive picture of a face and a specimen for comparison are unlikely to have been taken from the same angle, been captured under the same lighting conditions, posed with the same facial expression, etc. Fortunately for those in the business of matching images, there is a vast amount of experience on which to draw, not least from the gaming and film industries: CGI is now able to complete films in which an actor has died during filming or extend the oeuvre of long-dead film stars.
A similar challenge faced Solution Seeker: although large oil and gas production datasets have been accumulated, data volume is typically low for individual wells. A key component of the step-change from AI in the 1990s to state-of-the-art ML and DL is the ability to prepare data for the machine. Solution Seeker has developed a transfer learning model that is able to learn continuously across thousands of wells, utilising the resulting dataset as its exemplars. This modelling approach enables, for instance, a cost-efficient and high-quality Virtual Flow Meter.
The ‘Long and Wide’ of It
Bzdok et al. in their paper ‘Statistics versus Machine Learning’ characterise the difference between AI, or specifically Machine Learning, and classical statistical methods, as ML methods are particularly helpful when one is dealing with ‘wide data’, where the number of input variables exceeds the number of subjects, in contrast to ‘long data’, where the number of subjects is greater than that of input variables. This is another way to think of the dependence of ML and DL on greatly increased computing power. In the 1990s, there was insufficient computing power available to look at all the possible interactions between the parameters in a very large input dataset. NN were therefore necessarily used in a more classical statistical sense and indeed NN methods were often taught as just another multivariate statistical technique alongside Cluster Analysis, Principal Components Analysis and Factor Analysis. It is therefore, in part, the way in which NN are now used that provides a step-change from the 1990s to applications such as Solution Seeker.
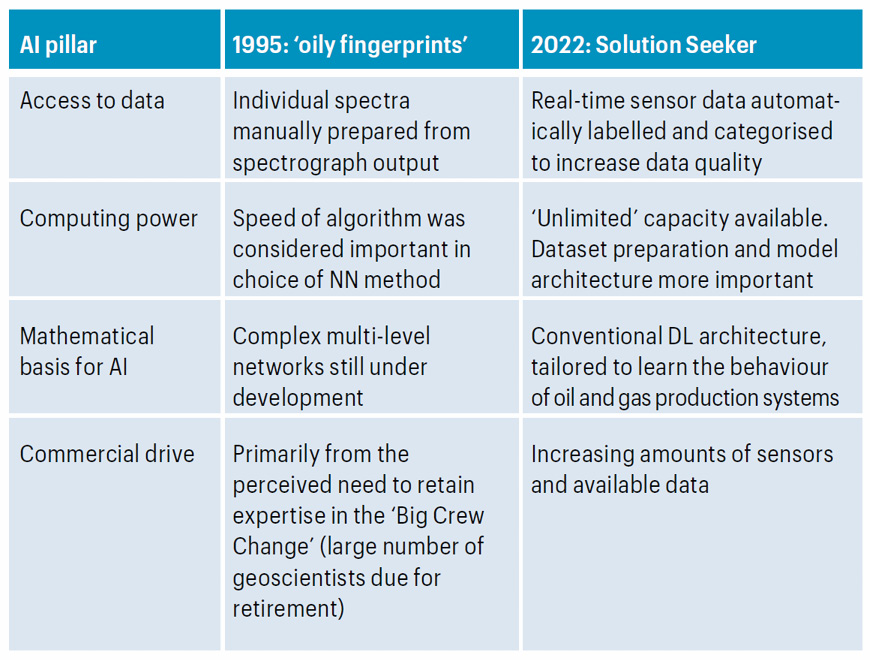
Table: AI: Then and Now.
With this step-change we have moved further from being able to ask the NN the crucial question “Why?”: why a prediction was made, what were the reasons. We are, however, now better able to ask how good the prediction is, in a similar way to placing predicted error bounds on methods from mathematical statistics. It is routine to predict permeability from porosity using linear regression, a practice necessitated by the comparative ease of obtaining porosity estimates, relative to the difficulty and expense of obtaining permeability measurements. Linear regression has an associated error estimate, which allows confidence bounds to be placed on a predicted value of permeability (assuming, of course, absolute accuracy in the inputs).
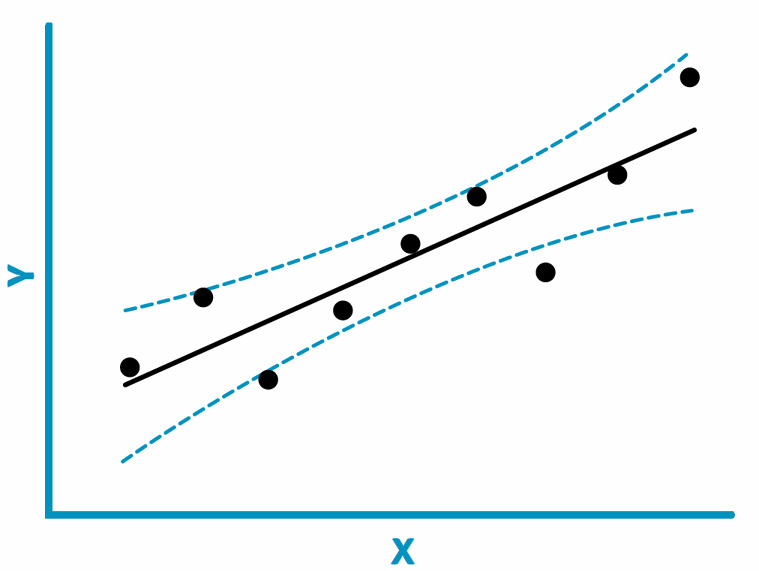
Error bounds on linear regression prediction. Credit: Dr Barrie Wells.
Similarly, a method to estimate or predict flow rates, such as that of Solution Seeker, is predicated on the relative ease of obtaining measurements which may then be used to model flow rates. At present, such predictions are not used routinely. Confidence in their use should increase with availability of reliable error bounds. Probabilistic error bounds may be calculated, by treating the weights in the NN as random variables for generating probabilities.
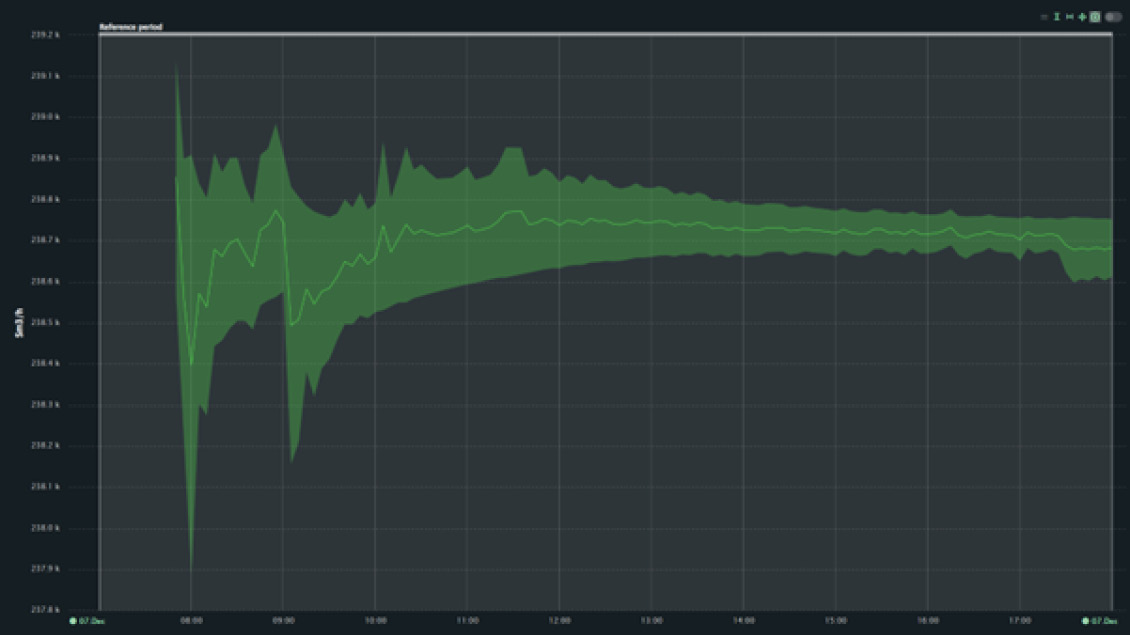
Uncertainty based on a data-driven ML (Virtual Flow Rate). Source: Solution Seeker.
AI – A Tool for the Geoscientist, not a Replacement
Machine Learning and Deep Learning are terms that are used to describe new ways of taking advantage of the implementations of mathematics and mathematical statistics comprising the methods under the umbrella of Artificial Neural Networks. They are capable of providing surprising results and are sufficiently far advanced technologically to sometimes appear to be indistinguishable from magic, if we do not appreciate the simple building blocks of NN and the addition of large datasets for training or learning.
It has taken a while for ML / DL to attain a level of usefulness in E&P, but now we expect to see a rapid expansion in deployment, based on the relative simplicity to scale across assets.
The main drawback of ML and DL is that we currently have no way to interrogate the engine, to ask why a certain conclusion was reached or on what basis certain inputs are considered to be similar. This places even greater importance on the role of the domain expert, the geoscientist, and means that, for the foreseeable future, AI will not replace good geoscientists; it should instead enhance their capabilities.
References
- Braunschweig, B. and Bremdal, B. 1995 and 1996. Artificial Intelligence in the Petroleum Industry: Symbolic and Computational Applications. Vols 1 (ISBN: 9782710806882) and 2 (ISBN: 9782710807032). Editions Technip.
- Hatton, R., Duller, A., Wells, B. and Barwise, A. 1995. Application of Neural Networks in Crude Oil Fluorescence Fingerprinting. ‘Best Paper’ at AI Petro, Lillehammer, Norway, September 1995.
- Bzdok, D., Altman, N. and Krzywinsk, M. 2018. Statistics versus Machine Learning. Nature Methods, 15(4), pp.233–234.



