
Artificial Intelligence – Its Use in Exploration and Production – Part 2
Machine Learning: magical or mathematical statistics? De-mystifying AI and setting it in a geo-exploration context.
When film studios remake classic films, critics and audiences often ask why. GEO ExPro has previously printed articles on AI, most notably a three-part series in 2017, thus the reader might ask what this current series of articles can add. One response could be that much has changed in five years, and there is discussion to be had on these advances. But that is not the main point of this series. My purpose, when I set out, was first to de-mystify AI, in particular in its current incarnation as Machine Learning (ML), and then to set it in a geo-exploration context.

The former is difficult, as there is an impenetrable mystery at the heart of ML – we have no way, certainly at present and probably ever, of understanding why a ML AI makes the decisions it does. We can investigate around the periphery and perhaps discover useful clues: for example, the US government facial recognition software that failed to recognise faces that aren’t Caucasian was trained on unrepresentative images, but we do not know the exact decisions the software was making during failures. Or, more relevant to this article, perhaps a porosity-permeability predictor was trained solely on clastic examples and so was unprepared for dealing with vugular porosity.
What is Machine Learning Really?
To set in a geo-exploration context is difficult, not least because there is no agreement on exactly what Machine Learning is. Stanford University defines ML as ‘the science of getting computers to act without being explicitly programmed’. It is still not entirely clear, because the word ‘explicitly’ is not clearly defined. We are probably better-off thinking of examples: Satnav that stops telling you to turn right when it has observed you followed this route successfully on previous occasions; predictive texting that remembers that the last time you used the words ‘I’m going’ they were followed by ‘home’, are both illustrative of what we have come to expect from AI, but are they ML? Is the machine learning?
The Satnav must have been explicitly programmed to know the number of times you needed to have followed that same route before it would stop telling you to turn left. Further, the entire effect could be achieved using just an ‘if…then…else’ Expert System approach. In the latter example, the machine has learnt from our answers when we were offered options, but still we could see how it works: if we repeatedly changed our response from ‘home’ to ‘out’, then this would become the AI’s first choice. So, what is it about ML that is impenetrable?
Neural Networks – Driving the Current AI Renaissance
We now associate ML almost exclusively with Neural Networks (NN) or Genetic Algorithms. Indeed, Massachusetts Institute of Technology (MIT) defines ML as a subset of AI that is based on NN. So, whilst AI encompasses everything from expert systems through to deep learning, and therefore includes Satnav and predictive texting, it is NN that are driving the current AI renaissance and it is within NN where there is an impenetrable mystery at the heart of ML.
That impenetrable mystery aside, we do need to understand that ML is not magic. Clarke’s third law says that ‘Any sufficiently advanced technology is indistinguishable from magic’. To an early 20th-century geoscientist, remote sensing of the subsurface would have seemed like magic. Wireline logs and geophysical seismic surveys are not magic, but few of us fully understand the inner workings of a sonde (or, nowadays, more likely a measurement while drilling (MWD) tool). We should, however, know enough to be able to appreciate the limits of the data in our analyses. Knowing that a tool scatters neutrons into the surrounding rock should be enough to appreciate that the resultant measurement is of a large volume of rock. We do not need to understand the rate at which neutrons
slow due to collision with formation nuclei, we just want to know the resolution of the tool, or the support (a geostatistical term for how much rock is being sampled to deliver a single measurement); which is around 2 ft vertically from the point of measurement. This is the level of understanding I am aiming at for these articles. The other part of this analogy is that we will want to know, later, about the support of a log tool, but again just in principle.
Predicting Permeability from Porosity
Returning to Archie versus AI from ‘AI – Its Use in Exploration and Production. Part 1’ (GEO ExPro Vol. 19, No. 1), and human intelligence contrasted with machine intelligence, we can look a little deeper into how NN work. By looking at a similar example, predicting permeability from porosity, we can examine why the reasons behind their conclusions are impenetrable.
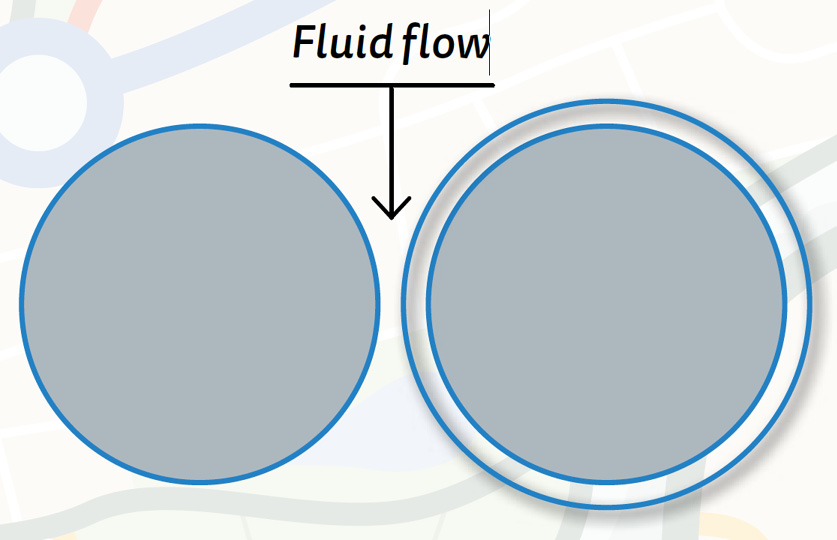
Figure 1: Grain overgrowth.
A geoscientist would not need to look at data to realise that the relationship would not be linear. Therefore, it is usual to try to estimate the form first, transform the data to linear, and then use statistics. This is where the human mind can take advantage of knowledge of the physical process: Archie had a good idea of what form he wanted, from knowledge of the physics. We can see that porosity and permeability must be related in a non-linear way, simply from the geology and the geometry.’ Heuristically, consider a mineral overgrowth on a grain (Figure 1).
In 2D, for simplicity, we see that, as an overgrowth increases the grain size (and hence decreases the pore space) in proportion to the square of the radial change, the pore throat width, which is the critical dimension for permeability, decreases only linearly. Whilst it is a more complicated geometrical exercise in 3D, and considerably more complicated if we also take account of grain size and shape, it is nevertheless clear that we should seek a non-linear relationship. Referring back to Archie in Part 1 of these articles, if we were doing this using traditional computer-based methods, we would try different forms of the relationship (cube root, logarithmic, etc.) as well as different parameters for each (by which I mean the ‘a’ and ‘b’ and ‘c’ in an equation such as y = ax2 + bx + c), and then look for a combination that best fits the available data.
A NN would not treat this as separable steps, looking instead for abstract relationships connecting the input data (observed porosity, together with grain size and shape or tortuosity information) with the output (the permeability that was observed). A useful analogy is principal components analysis (PCA). This is a classical statistical method. It is not a learning algorithm; it gives the same answer every time, just as 2 + 2 is always 4. But in some ways the first principal component (PC) has more in common with a NN output than with a simple regression output (even though the first PC is the reduced major axis (RMA) regression line in 2D), because it is not, in general (i.e., in more than two dimensions), physically explainable in the same way as we can explain the individual steps of picking a functional form and then finding the parameters.

Blindly Searching for the Best Fit with the Data
The NN is better than human intuition backed up by traditional statistical calculations, in that the NN will try many more combinations and possibilities than a human ever could, but we cannot pick apart the steps to understand why it made the choices it did; its reasoning is impenetrable, blindly following a search for the best fit with the data.
Which brings us right back to consideration of what is ‘best’. We have to have a definition of ‘best fit’, or, more generally, an objective function, a measure against which each attempt by the NN can be measured. In games such as Go and Chess, this is simple: a win is good, a loss is bad. How are we to achieve this in exploration when we usually don’t know the answer?
In this dataset, we could use traditional statistical tools such as cluster analysis or discriminant analysis to try to determine how many distinct groups there are. The problem then is knowing when to stop.

Plotting the improvement, as a graph of our measure of ‘good’ against the number of groups, may identify a critical point and hence an optimum number of groups, but more usually this is far from clear. Geologists know this problem as lumpers versus splitters: at the microscopic level, every sample of rock is different, but to make progress in modelling and analysis we have to allow some amount of difference within a facies or formation. There is no correct answer: the geologist’s answer rarely gets past the engineer and into the reservoir simulator model.
In statistical analysis, a distinction is made between unsupervised and supervised: allowing the software to find the optimum clustering (unsupervised) or telling the software the answer for a set of training examples and letting it classify new cases into one of these pre-determined classes (supervised). Supervised learning gets round the problem of lumping versus splitting but reduces the ability of the AI to spot things in the data that we did not expect.

One More Example
If we provide a set of examples (and one log run, as above, is a set of examples, it doesn’t have to be multiple runs) in which we have given an answer at each point, then the NN can identify data combinations that are diagnostic of each answer. This is supervised. Alternatively, we might just give the NN the data and ask it to pick categories. This is unsupervised. In the latter case, the NN could easily provide a reason to distinguish every single data point as its own category: even if the values of all traces are identical, the gradient and higher order derivatives will not be identical. So, we still must supervise in the sense of arbitrating between lumping and splitting but we do have the possibility of finding new information. If the NN picks an extra facies, it could be that it has detected a thin bed, below the resolution of the tools, or it could just be trying to make sense of noise. Only we can tell, from our knowledge of the support and resolution of each tool.
So, has this Neural Network demonstrated learning? At this point, I would argue that it has not, and in Part 3 I will expand on how NN lead to ML and hence where the learning comes in.
More In This Series…
Artificial Intelligence – Its Use in Exploration and Production – Part 1
Dr Barrie Wells, Conwy Valley Consultants
What is it really and what are its limitations?
This article appeared in Vol. 19, No. 1 – 2022



