Deep learning is a subset of machine learning, which entails a neural network with three or more layers. It is thanks to deep learning that applications from fault picking to prediction of log properties have proliferated. However, as set out in this article, it is important to always validate results before drawing conclusions.
There are two primary validation methods that can be used for machine learning applied to geophysical data and seismic data in particular: 1) geological confirmation by a human interpreter and 2) out-of- sample well validation.
The interpreter’s call
Geological confirmation by an interpreter is relatively straightforward. If a fault detection algorithm is applied, the interpreter can simply check whether the faults appear on the input data and validate them, as a senior interpreter would be working with a junior interpreter. In supervised learning, corrections can be made from which the algorithm can “learn” and improve its future performance in fault picking. This type of automated interpretation generally entails low risk since the output can be checked directly by the interpreter.
Similarly, with rock properties prediction or resolution enhancement for the purpose of stratigraphic interpretation, the interpreter should confirm the geological character of the results and that there is correspondence between the events in the input seismic data and the output prediction or enhancement.
To enable this, the interpreter can familiarize himself/herself with the change in response between low frequency events and high frequency (resolution enhanced) events using a set of modeled reflectivity configurations. Resolution enhancement should not create new events, although exceptionally thin low impedance sands will become more evident. Figure 1 shows the Widess tuning curve with thin low impedance/low amplitude sands on the left.
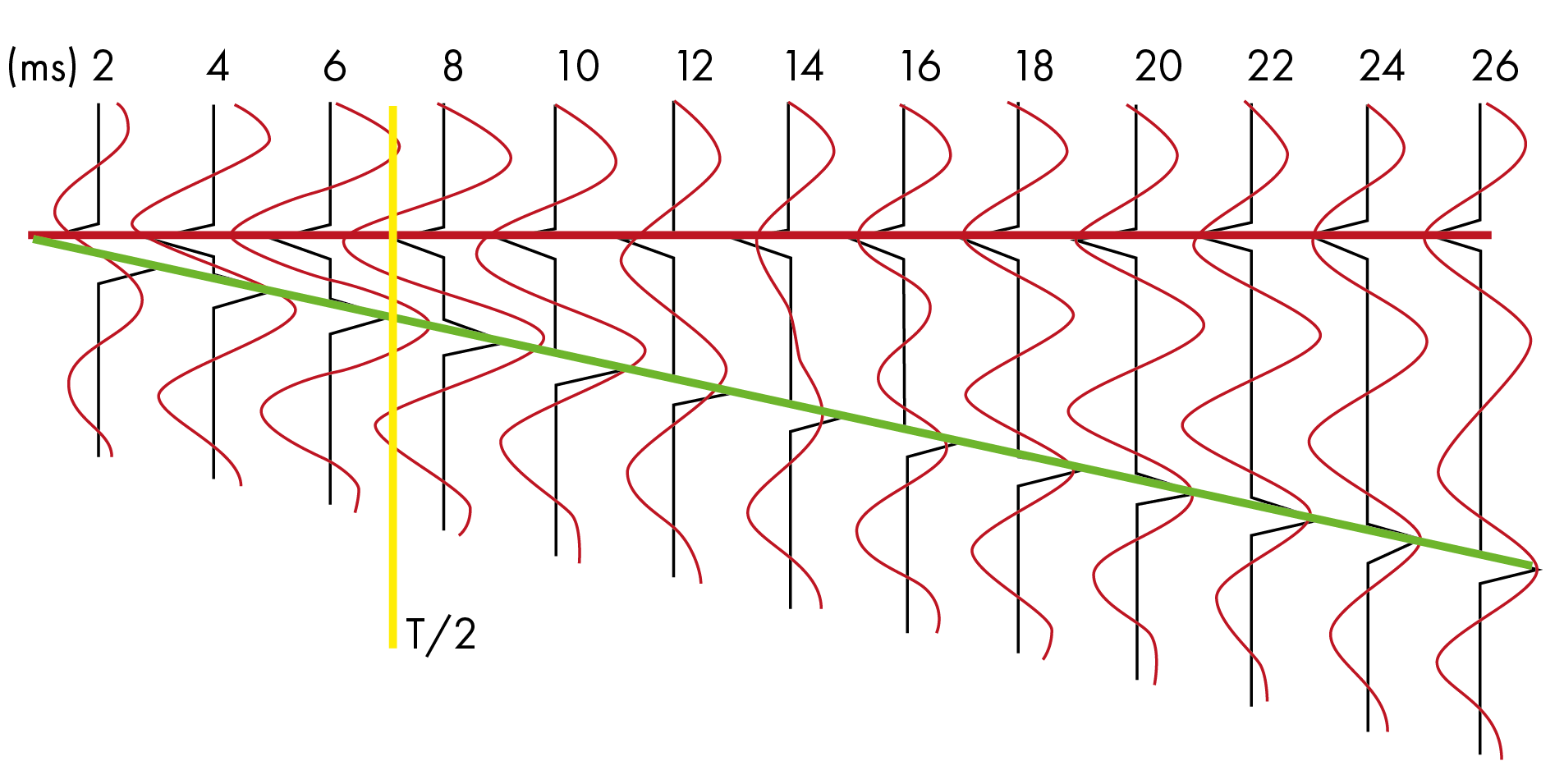
Events should never disappear or get “wiped out” with resolution enhancement – although they can bifurcate. If the output appears inconsistent with the input or contains artifacts, out-of-sample validation should be applied.
Out-of-sample validation
There are two types of validation using a set of logs for 3D properties prediction: in-sample validation and out-of-sample validation (Figure 2).
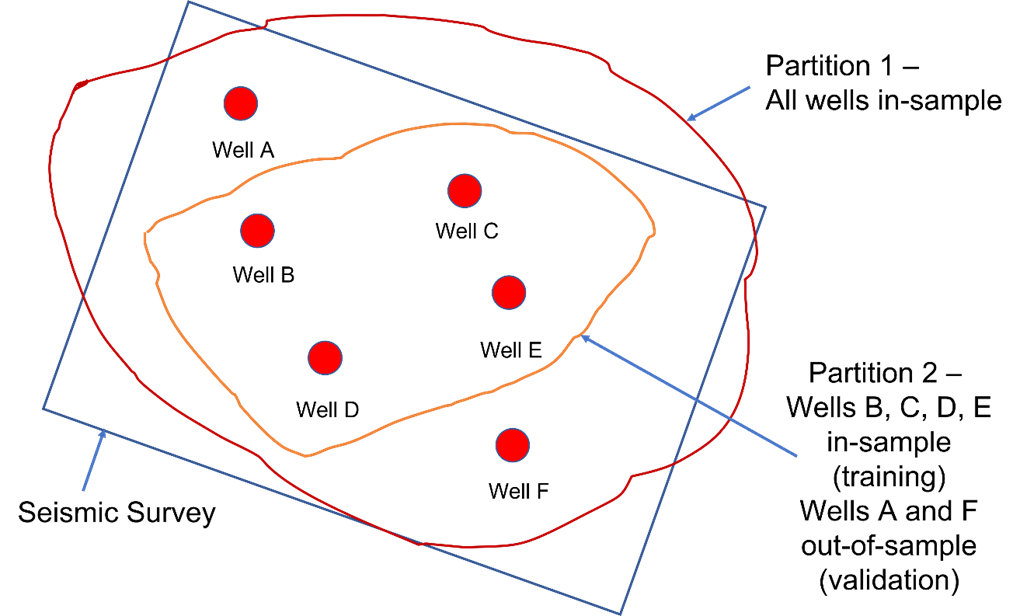
In-sample validation simply means using the training data for validation; it is a trivial QC on the machine learning model and does not provide any meaningful indication of its predictive power. On the other hand, out-of-sample validation entails removing part of the dataset – for example, one or more wells – for validation. While it is generally desirable to partition the data at 80% training/ 20% validation, this is often not possible at the oil and gas exploration stage. Thus, we frequently suffer from a shortage of training data. Once the model is defined using the training data, it can be applied to the validation data in order to evaluate its performance.
Using in-sample validation only, nearly perfect well ties are achievable with machine learning properties prediction or resolution enhancement. However, if out-of-sample validation is neglected, the predicted data result could be synthetic “high resolution” data that deviate significantly from test wells drilled after the analysis; strictly speaking, out-of-sample validation does not guarantee that this will not happen either.
…if out-of-sample validation is neglected, the predicted data result could be synthetic “high resolution” data…
Consider a target unit with different rock properties that pinches out without being sampled by any wells; this unit cannot be used at all in the training process and the application of machine learning to predict its rock properties would be unreliable. These techniques are also sensitive to the input well tie quality and prone to artifacts if not properly parameterized.
In commercial settings, we recommend a “trust but verify” approach; at least one validation well should always be withheld from the vendor doing the machine learning or resolution enhancement analysis. If no wells, few wells or only low quality well curves are available, we recommend a signal processing approach such as Spectral Extrapolation for resolution enhancement, which does not require well information but can be used for phase
calibration.
When drilling a new well based on machine learning prediction results, the final cost of inadequate prior well sampling or mixing the training and validation datasets could run into the tens of millions of dollars.