Seismic facies classification can be a tedious process, especially in an exploration context where large areas need to be assessed. In order to speed up that process, using a library of seismic facies patterns from a benchmark dataset can help map the 3D distribution of seismic facies in an automated way.
Hui Gui, representing a group of researchers from the University of Science and Technology of China (Hefei), gave a talk at the recent IMAGE Conference in Houston, during which he illustrated how a large collection of benchmark seismic facies patterns was put together. Both the datasets and the codes have been made available online for anyone interested to know more.
How to built it?
But how to make sure that a library of seismic facies patterns covers the diversity observed in the real world? In order to do that, the team worked with a three-tier strategy.
First of all, they built a portfolio of characteristic seismic facies from public domain data. These datasets, being from different seismic vintages and areas, were standardized through a spectral analysis exercise.
Due to the lack of diversity in examples from public domain sources, as a second step the authors also generated synthetic facies samples based on prior knowledge of seismic facies. But even though a noise factor was introduced in this process to arrive at a more real-world representation, this dataset still suffered from a lack in diversity and realism.
To overcome the issue, as a final step, the team used the images generated in the first and second stages as training datasets to train a so-called GAN model. The progressive growing of a GAN model consists of a generator model (G) and a discriminator model (D), where G is used to capture the data distribution and generate fake images to resemble the training dataset, and D is used to assess the probability that images are real or fake. This training strategy allows the network to learn the features of the training dataset from large to small scales, resulting in faster training speed, higher stability, and better-quality images. After training the GAN model, the generator model (G) was used to automatically generate diverse samples.
The test
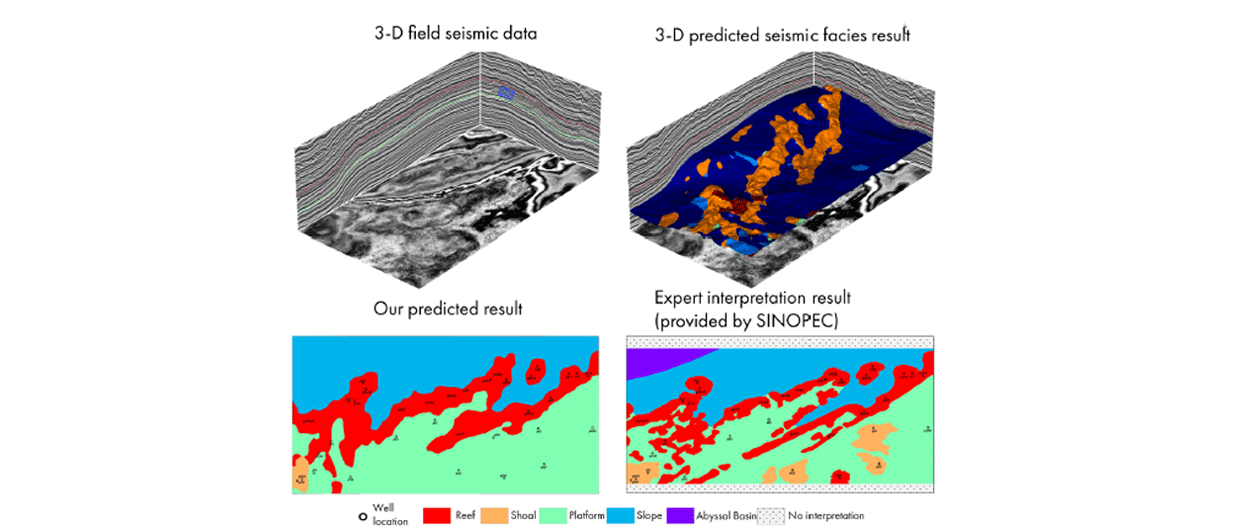
The authors subsequently showed how the model was applied to a 3D seismic dataset using the Yuanba 3D as an example – shown here. They showed that an expert interpretation of a series of carbonate reefs and slope areas were correctly predicted by the model.
During the Q&A, someone from Chevron remarked that the benchmark dataset seemed to have been built using unfaulted seismic data, implying that faults may hinder the automatic interpretation process. The author replied that this will be part of future work.