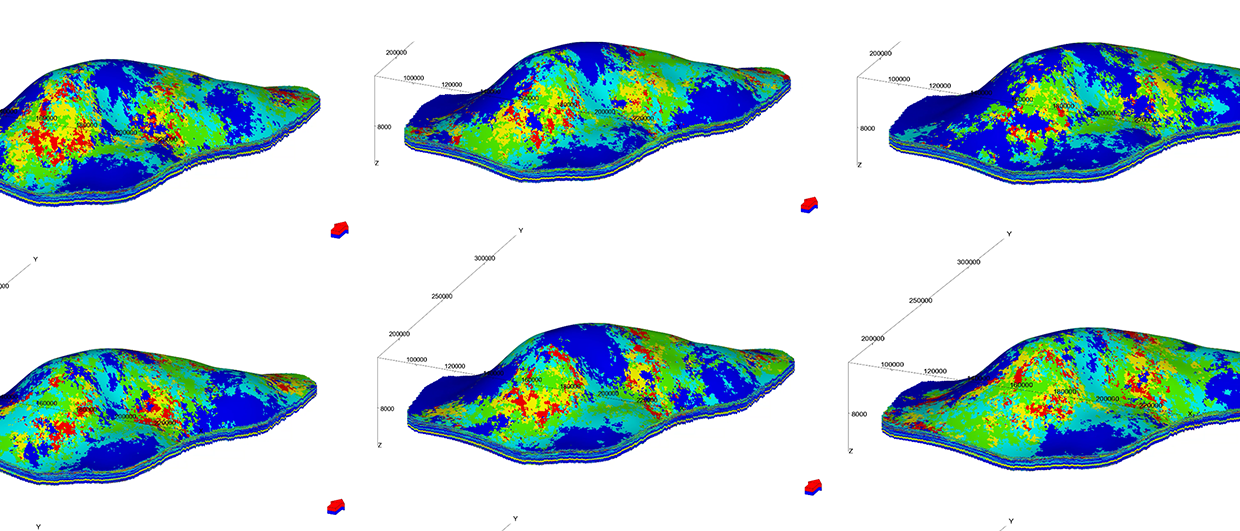
Exploring Uncertainty in Subsurface Modelling and Forecasting
Ensemble-based modelling has been delivering value to the E&P industry for over ten years, causing a fundamental re-think of what exactly is needed to more accurately forecast the future behaviour of a reservoir’s performance and enable better decisions to be made on developing and managing the production of hydrocarbon assets.
The oil and gas exploration and production industry has transitioned from the legacy concept of a single case model of the subsurface, which was always doomed to be proven wrong at some time in the life cycle of a producing reservoir. This was due to the sparseness of the data, the noise inherent to the data collection process, and the cognitive biases that are intrinsic to the processing and interpretation of raw measured data. The need to quantify uncertainties became the next frontier, and many different methods were developed and deployed to improve the outcomes. However, this did not translate into a significantly better ability to forecast the future behaviour of a reservoir’s performance.
High Stakes
To put this in context, we are deploying a complex process that takes a significant effort to provide predictive information that drives investments of hundreds of millions into infill drilling, injection programmes or other production management activities. Yet seldom is a rigorous and scientific appraisal of available data used to reach conclusions. Instead, convictions based on experience and comparisons to analogous petroleum systems become part of the decision process. While such empirical choices are necessary to jump-start projects and point the modelling process in a certain direction – what we would call a base modelling hypothesis – the error consists in promoting these initial assumptions from a status of educated guess to one of fact.
Overcoming Cognitive Bias
Beyond the flawed search for complexity characteristic of the single case model, its salient limitation is the excessive application of cognitive bias towards delivering a “best” solution.
Two main approaches have been used to overcome this:
- The multiple stochastic approach uses an automated framework to model realisations using probability distributions of the unknown reservoir parameters.
- The multiple scenario approach uses a manual or semi-automatic method to build deterministic models.
Each approach has strengths and weaknesses that can restrict the efficiency, scalability and validity of the method and the resulting models.
Systematically Managing Uncertainty
Cognitive biases are most at play in the single case model approach, in which the team needs to arbitrate choices and resolve uncertainties across the whole workflow before delivering the single result. The multiple stochastic approach requires a base hypothesis at inception, e.g., a zonation scheme or depositional environment, but the ensuing automated process is repeatable. The multiple scenario approach can use a choice of a different base hypothesis for some or all scenarios. However, the user is tasked with providing inputs to parameters and with steering the workflow to deliver the final model, which is feasible at an asset’s early ‘greenfield’ stage as static data prevails. As complexity increases for mature ‘brownfields’ the process takes more and more time and is increasingly difficult to manage systematically.
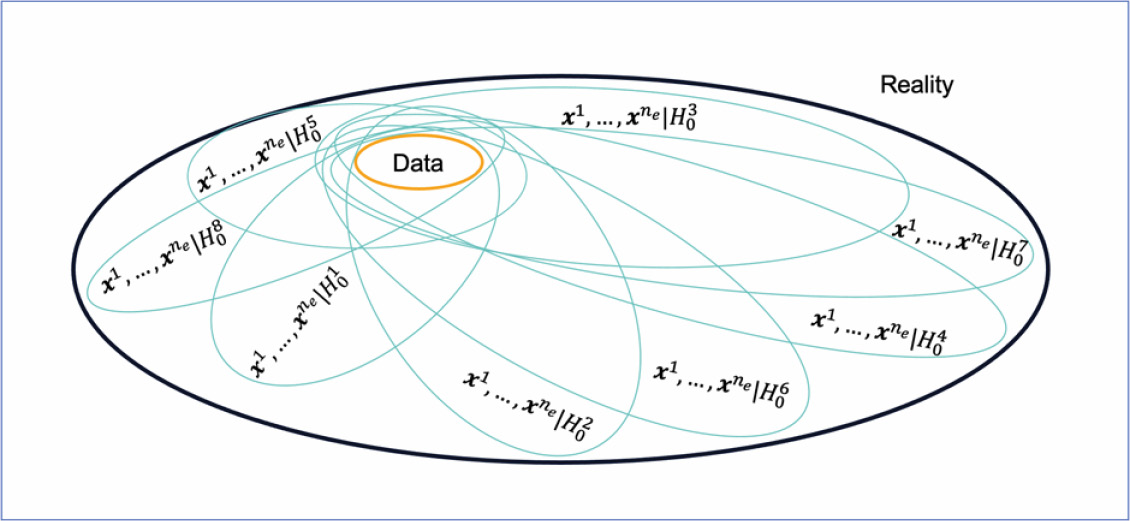
Figure 1: The uncertainty “space” encompassing all the possible ensemble-based models originating from the same data but using different base hypothesis. Credit: Resoptima.
The comprehensive and scientifically rigorous solution is a combination of the repeatable methods of the multiple stochastic approach with the exploratory nature of the multiple scenario approach. The multiple stochastic approach is initialised with a given modelling hypothesis, and this risk is mitigated by exploring the whole space of possible ensemble-based models by evaluating multiple modelling hypothesis, all of which are plausible given the current data measurements.
This will correspond to a methodical exploration of the whole uncertainty space as illustrated in Figure 1.
This brings up another valid concern: if one run of ensemble-based modelling for an asset takes a few weeks, how can we execute numerous ensemble-based modelling runs, and perform comparisons to derive conclusions from this volume of data, knowing that the workload has grown ten-fold or more?
Speeding Up the Process
We need to further change our mindset regarding reservoir model building. Parkinson’s Law, articulated in 1955, stated that ‘work expands to fill the time available for its completion’. Over the years, as single case models have increased in complexity, a duration of many months became the norm for such projects. Ensemble-based modelling starts with an initial model that is only as complex as needed to honour the data and is therefore simpler and faster to produce – typically a matter of weeks. Faced with the need to generate tens of ensembles, it was possible to bring the time down to a few days:
- Data curation can be made both more effective and less time-consuming by performing it concurrently and as a team as opposed to one data type at a time and in isolation.
- Ensemble-based modelling has always favoured starting with a model as simple as possible but not too simple, adding complexity only if the data dictates it.
- Finally, the construction of the workflow was given a very short time to come to fruition, in the order of two days, which in practice proved possible and broke from customary times of weeks or even months. Experience had shown that spending too much time on highly complex and detailed workflows was often thwarted by a realisation on completion that the process was invalidated by wrong assumptions related to the input data.
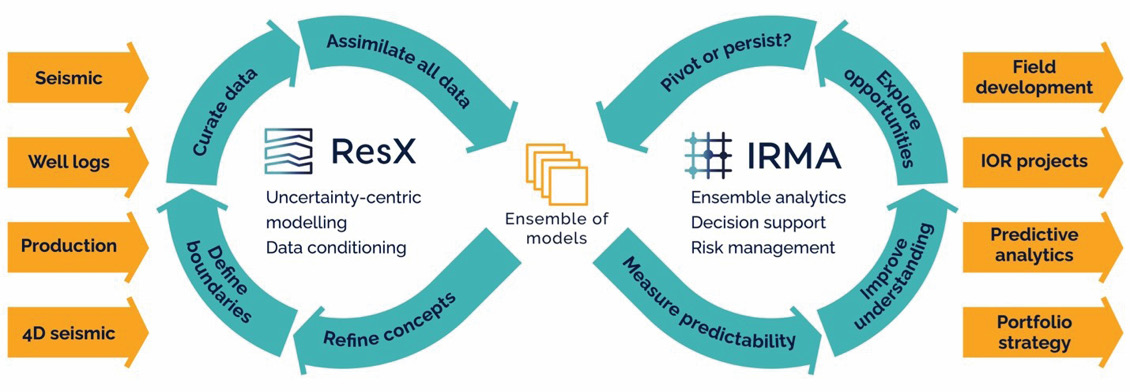
Figure 2: Ensemble-based modelling coupled to ensemble analytics. Credit: Resoptima.
Best practices can now be changed with the adoption of the sprint concept that is used in software development. An ensemble-based modelling sprint (Figure 2) will focus on generating multiple ensembles using often fundamentally different modelling hypothesis, with the goal of providing specific deliverables with a quantification of the prediction error.
Delivering Value
Ensemble-based modelling has been delivering value to the E&P industry for over ten years, causing a fundamental re-think of what exactly is needed to make decisions on developing and managing the production of hydrocarbon assets, namely a better grasp of uncertainties across hundreds of data- conforming realisations instead of an obsessive focus on detail within a single model. The mandate is now expanded to the appraisal of the whole space of uncertainties associated with different initial hypothesis for an ensemble, within the scope of short sprints focused on specific challenges.